3D仿真强化学习
一、引入神经网络
1. 什么是神经网络
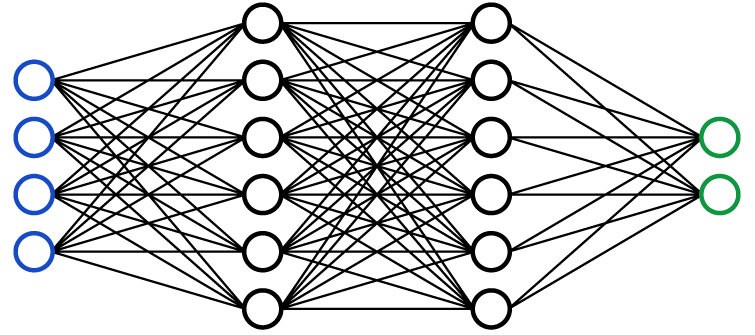
神经网络是一种模仿生物神经系统结构和功能的计算模型,广泛应用于机器学习、人工智能等领域。它由大量相互连接的节点(也称为“神经元”)组成,这些节点通常被组织成多个层次,包括输入层、隐藏层和输出层。
- 输入层:负责接收外界信息或数据,并将其传递给网络的下一层。
- 隐藏层:位于输入层和输出层之间,可以有一个或多个。隐藏层中的神经元通过调整权重来处理输入数据,提取数据特征。
- 输出层:最终处理结果在此层输出,根据网络的任务可能是分类标签、数值预测等。
神经元之间的连接都有一个与之相关的权重,网络通过调整这些权重来学习如何将输入映射到输出。这一过程通常涉及到一种叫做反向传播的技术,结合梯度下降算法来最小化网络预测值与实际目标值之间的误差。
神经网络的一个重要特点是它们具有从数据中自动学习的能力,无需明确编程就能识别模式。这使得它们非常适合于解决那些传统基于规则的方法难以处理的问题,比如语音识别、图像分析、自然语言处理等。
2. 为什么要用神经网络
- 根基动作设计上的困难:传统的优化是先得人工设计一个关键帧动作模板,再使用CMA-ES算法优化模板中的参数来达到更好的效果,模板的好坏直接决定动作的上限
- 不良的动作模板的高精度定位要求在时间消耗方面的挑战:如果设计的模板适应性能力弱,则执行该动作时必须让机器人尽可能对准某个位置进行踢球才能踢的好,
尽可能对准这个行为会导致定位的区域被限制的很小,可能很长时间才能完成定位 - 动作的稳定性问题:人工设计的模板很难实现连贯的动作,几乎无法实现人类踢球一样自然的动作,通常来说,
不自然也意味着动作不稳定,可能这次踢10米下次就踢不出去
3. 神经网络如何应用到3D仿真
大家只需要把神经网络当成一种神奇的黑盒,或者是一个不知道表达式的函数f(x),x是我们输入到神经网络的东西,函数的计算结果即表示神经网络的输出,结合强化学习的框架,神经网络会被很好的应用
4. 我必须完全搞明白神经网络才能去优化3D吗?
没这个必要
二、强化学习
概述(来自通义千问)
强化学习(Reinforcement Learning, RL)是机器学习中的一个领域,它关注的是如何让软件代理在特定环境中通过执行动作以最大化某种累积奖励。强化学习的基本思想来源于心理学中的行为主义理论,即通过与环境的交互来学习最佳的行为策略。
强化学习的核心概念包括:
- 代理(Agent):指的是学习和做出决策的实体。
- 环境(Environment):代理所处的世界或场景,代理通过与其互动来学习。
- 状态(State):描述了环境在某一时刻的情况。
- 动作(Action):代理根据当前的状态选择要执行的操作。
- 奖励(Reward):环境给予代理的反馈,用来评估该动作的好坏。
- 策略(Policy):代理决定在给定状态下采取何种行动的规则或方法。
- 价值函数(Value Function):预测从当前状态开始,按照某策略进行下去所能获得的总奖励。
强化学习的目标是找到一种策略,使得代理能够获得最大的累积奖励。这通常涉及到探索(exploration)和利用(exploitation)之间的权衡:探索未知的动作以发现更好的策略,以及利用已知的信息来获取即时的奖励。
强化学习的一个关键特点是它的试错性质,代理通过不断尝试不同的行动并接受来自环境的反馈来学习最优策略。这种学习方式使得强化学习非常适合解决一些复杂的、没有明确解决方案的问题,如游戏玩转、机器人导航、资源管理等。
| 名词 | 对应到3D | 备注 |
|---|---|---|
| 代理(Agent) | 机器人这个可以与球场传递信息的个体 | |
| 环境(Environment) | 3D仿真环境(包含球场各类信息,球员位置,球位置,速度等) | |
| 状态(State) | 状态空间(优化中作为神经网络的输入) | |
| 动作(Action) | 动作空间(优化中作为神经网络的输出) | |
| 奖励(Reward) | 机器人执行一次测试(踢球)的结果打分(踢的距离,误差角度之类的综合打分) | |
| 策略(Policy) | 探索的策略,一般使用PPO | |
| 价值函数(Value Function) | 这个没听说过,不管了 |
成功案例
感谢南邮Apollo开源的优化脚本:https://github.com/Jiangtianjian/Kick-Train-Env/blob/main/scripts/gyms/kick.py
脚本解读
from random import random
from agent.Base_Agent import Base_Agent as Agent
from behaviors.custom.Step.Step import Step
from world.commons.Draw import Draw
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import SubprocVecEnv
from scripts.commons.Server import Server
from scripts.commons.Train_Base import Train_Base
from time import sleep
import os, gym
import numpy as np
from math_ops.Math_Ops import Math_Ops as U
from math_ops.Math_Ops import Math_Ops as M
from behaviors.custom.Step.Step_Generator import Step_Generator
'''
Objective:
Learn how to run forward using step primitive
----------
- class Basic_Run: implements an OpenAI custom gym
- class Train: implements algorithms to train a new model or test an existing model
'''
class Kick(gym.Env):
def __init__(self, ip, server_p, monitor_p, r_type, enable_draw) -> None:
self.lock_flag = False
self.sleep = 0
self.reset_time = None
self.behavior = None
self.path_manager = None
self.bias_dir = None
self.robot_type = r_type
self.kick_ori = 0
self.terminal = False
# Args: Server IP, Agent Port, Monitor Port, Uniform No., Robot Type, Team Name, Enable Log, Enable Draw
self.player = Agent(ip, server_p, monitor_p, 1, self.robot_type, "Gym", True, enable_draw)
self.step_counter = 0 # to limit episode size
self.ball_pos = np.array([0, 0, 0])
self.step_obj: Step = self.player.behavior.get_custom_behavior_object("Step") # Step behavior object
# State space
obs_size = 63
self.obs = np.zeros(obs_size, np.float32)
self.observation_space = gym.spaces.Box(low=np.full(obs_size, -np.inf, np.float32),
high=np.full(obs_size, np.inf, np.float32), dtype=np.float32)
# Action space
MAX = np.finfo(np.float32).max
self.no_of_actions = act_size = 16
self.action_space = gym.spaces.Box(low=np.full(act_size, -MAX, np.float32),
high=np.full(act_size, MAX, np.float32), dtype=np.float32)
# Place ball far away to keep landmarks in FoV (head follows ball while using Step behavior)
self.player.scom.unofficial_move_ball((14, 0, 0.042))
self.ball_x_center = 0.20
self.ball_y_center = -0.04
self.player.scom.unofficial_set_play_mode("PlayOn")
self.player.scom.unofficial_move_ball((0, 0, 0))
def observe(self, init=False):
w = self.player.world
r = self.player.world.robot
if init:
self.step_counter = 0
self.obs[0] = self.step_counter / 20
self.obs[1] = r.loc_head_z * 3
self.obs[2] = r.loc_head_z_vel / 2
self.obs[3] = r.imu_torso_roll / 15
self.obs[4] = r.imu_torso_pitch / 15
self.obs[5:8] = r.gyro / 100
self.obs[8:11] = r.acc / 10
self.obs[11:17] = r.frp.get('lf', np.zeros(6)) * (10, 10, 10, 0.01, 0.01, 0.01)
self.obs[17:23] = r.frp.get('rf', np.zeros(6)) * (10, 10, 10, 0.01, 0.01, 0.01)
self.obs[23:39] = r.joints_position[2:18] / 100
self.obs[39:55] = r.joints_speed[2:18] / 6.1395
ball_rel_hip_center = self.player.inv_kinematics.torso_to_hip_transform(w.ball_rel_torso_cart_pos)
if init:
self.obs[55:58] = (0, 0, 0)
elif w.ball_is_visible:
self.obs[55:58] = (ball_rel_hip_center - self.obs[58:61]) * 10
self.obs[58:61] = ball_rel_hip_center
self.obs[61] = np.linalg.norm(ball_rel_hip_center) * 2
self.obs[62] = U.normalize_deg(self.kick_ori - r.imu_torso_orientation) / 30
'''
Expected observations for walking parameters/state (example):
Time step R 0 1 2 0 1 2 3 4
Progress 1 0 .5 1 0 .25 .5 .75 1
Left leg active T F F F T T T T T
Parameters A A A B B B B B C
Example note: (A) has a step duration of 3ts, (B) has a step duration of 5ts
'''
return self.obs
def sync(self):
''' Run a single simulation step '''
r = self.player.world.robot
self.player.scom.commit_and_send(r.get_command())
self.player.scom.receive()
def reset(self):
# print("reset")
'''
Reset and stabilize the robot
Note: for some behaviors it would be better to reduce stabilization or add noise
'''
self.lock_flag = False
self.player.scom.unofficial_set_play_mode("PlayOn")
Gen_ball_pos = [random() * 5 - 9, random() * 6 - 3, 0]
Gen_player_pos = (random() * 3 + Gen_ball_pos[0], random() * 3 + Gen_ball_pos[1], 0.5)
self.ball_pos = np.array(Gen_ball_pos)
self.player.scom.unofficial_move_ball((Gen_ball_pos[0], Gen_ball_pos[1], Gen_ball_pos[2]))
self.sleep = 0
self.step_counter = 0
self.behavior = self.player.behavior
r = self.player.world.robot
w = self.player.world
t = w.time_local_ms
self.path_manager = self.player.path_manager
gait: Step_Generator = self.behavior.get_custom_behavior_object("Walk").env.step_generator
self.reset_time = t
for _ in range(25):
self.player.scom.unofficial_beam(Gen_player_pos, 0) # beam player continuously (floating above ground)
self.player.behavior.execute("Zero_Bent_Knees")
self.sync()
# beam player to ground
self.player.scom.unofficial_beam(Gen_player_pos, 0)
r.joints_target_speed[
0] = 0.01 # move head to trigger physics update (rcssserver3d bug when no joint is moving)
self.sync()
# stabilize on ground
for _ in range(7):
self.player.behavior.execute("Zero_Bent_Knees")
self.sync()
# walk to ball
while True and w.time_local_ms - self.reset_time <= 50000:
direction = 0
if self.player.behavior.is_ready("Get_Up"):
self.player.behavior.execute_to_completion("Get_Up")
self.bias_dir = [0.09, 0.1, 0.14, 0.08, 0.05][r.type]
biased_dir = M.normalize_deg(direction + self.bias_dir) # add bias to rectify direction
ang_diff = abs(
M.normalize_deg(biased_dir - r.loc_torso_orientation)) # the reset was learned with loc, not IMU
next_pos, next_ori, dist_to_final_target = self.path_manager.get_path_to_ball(
x_ori=biased_dir, x_dev=-self.ball_x_center, y_dev=-self.ball_y_center, torso_ori=biased_dir)
if (w.ball_last_seen > t - w.VISUALSTEP_MS and ang_diff < 5 and
t - w.ball_abs_pos_last_update < 100 and # ball absolute location is recent
dist_to_final_target < 0.025 and # if absolute ball position is updated
not gait.state_is_left_active and gait.state_current_ts == 2): # to avoid kicking immediately without preparation & stability
break
else:
dist = max(0.07, dist_to_final_target)
reset_walk = self.behavior.previous_behavior != "Walk" # reset walk if it wasn't the previous behavior
self.behavior.execute_sub_behavior("Walk", reset_walk, next_pos, True, next_ori, True,
dist) # target, is_target_abs, ori, is_ori_abs, distance
self.sync()
# memory variables
self.lastx = r.cheat_abs_pos[0]
self.act = np.zeros(self.no_of_actions, np.float32)
return self.observe(True)
def render(self, mode='human', close=False):
return
def close(self):
Draw.clear_all()
self.player.terminate()
def step(self, action):
r = self.player.world.robot
b = self.player.world.ball_abs_pos
w = self.player.world
t = w.time_local_ms
r.joints_target_speed[2:18] = action
r.set_joints_target_position_direct([0, 1], np.array([0, -44], float), False)
self.sync() # run simulation step
self.step_counter += 1
self.lastx = r.cheat_abs_pos[0]
# terminal state: the robot is falling or timeout
if self.step_counter > 22:
obs = self.observe()
self.player.scom.unofficial_beam((-14.5, 0, 0.51), 0) # beam player continuously (floating above ground)
waiting_steps = 0
high = 0
while waiting_steps < 650: # 假设额外等待5个步骤
if w.ball_cheat_abs_pos[2] > high:
high = w.ball_cheat_abs_pos[2]
self.sync() # 继续执行仿真步骤
waiting_steps += 1
dis = np.linalg.norm(self.ball_pos - w.ball_cheat_abs_pos)
reward = dis - abs(w.ball_cheat_abs_pos[1] - self.ball_pos[1]) + high*0.2
# print(reward)
self.terminal = True
else:
obs = self.observe()
reward = 0
self.terminal = False
return obs, reward, self.terminal, {}
class Train(Train_Base):
def __init__(self, script) -> None:
super().__init__(script)
def train(self, args):
# --------------------------------------- Learning parameters
n_envs = min(14, os.cpu_count())
n_steps_per_env = 128 # RolloutBuffer is of size (n_steps_per_env * n_envs)
minibatch_size = 64 # should be a factor of (n_steps_per_env * n_envs)
total_steps = 30000000
learning_rate = 3e-4
folder_name = f'Kick_R{self.robot_type}'
model_path = f'./scripts/gyms/logs/{folder_name}/'
# print("Model path:", model_path)
# --------------------------------------- Run algorithm
def init_env(i_env):
def thunk():
return Kick(self.ip, self.server_p + i_env, self.monitor_p_1000 + i_env, self.robot_type, False)
return thunk
servers = Server(self.server_p, self.monitor_p_1000, n_envs + 1) # include 1 extra server for testing
env = SubprocVecEnv([init_env(i) for i in range(n_envs)])
eval_env = SubprocVecEnv([init_env(n_envs)])
try:
if "model_file" in args: # retrain
model = PPO.load(args["model_file"], env=env, device="cuda", n_envs=n_envs, n_steps=n_steps_per_env,
batch_size=minibatch_size, learning_rate=learning_rate)
else: # train new model
model = PPO("MlpPolicy", env=env, verbose=1, n_steps=n_steps_per_env, batch_size=minibatch_size,
learning_rate=learning_rate, device="cuda")
model_path = self.learn_model(model, total_steps, model_path, eval_env=eval_env,
eval_freq=n_steps_per_env * 20, save_freq=n_steps_per_env * 20,
backup_env_file=__file__)
except KeyboardInterrupt:
sleep(1) # wait for child processes
print("\nctrl+c pressed, aborting...\n")
servers.kill()
return
env.close()
eval_env.close()
servers.kill()
def test(self, args):
# Uses different server and monitor ports
server = Server(self.server_p - 1, self.monitor_p, 1)
env = Kick(self.ip, self.server_p - 1, self.monitor_p, self.robot_type, True)
model = PPO.load(args["model_file"], env=env)
try:
self.export_model(args["model_file"], args["model_file"] + ".pkl",
False) # Export to pkl to create custom behavior
self.test_model(model, env, log_path=args["folder_dir"], model_path=args["folder_dir"])
except KeyboardInterrupt:
print()
env.close()
server.kill()
脚本改进
请看FCPCodebase仓库的issue:https://github.com/m-abr/FCPCodebase/issues/30
用浪潮集群来优化
请看:https://www.tansor.it/机器学习/在浪潮AiStation上部署RoboCup3D深度强化学习环境/